# data
n = 24
xBar = 12.5
s2 = 3.1^2
# prior
mu0 = 8
kappa0 = 5
nu0 = 3
sigma02 = 1^2
# posterior
w = n/(kappa0 + n)
mun = w*xBar + (1-w)*mu0
kappan = kappa0 + n
nun = nu0 + n
sigman2 = (nu0*sigma02 + (n-1)*s2 +
(kappa0*n/(kappa0 + n))*(xBar - mu0)^2 )/nunChapter 3 - Multi-parameter models: Exercise solutions
Click on the arrow to see a solution.
Exercise 3.1
A dataset contains observations on measurements of pesticide for \(n=24\) pike fish in a lake in southern Italy. The sample mean pesticide level is \(\bar{x} = 12.5\) with a sample standard deviation of \(s=3.1\). Assume that the pesticide levels \(X_1,\ldots,X_n|\theta,\sigma^2 \sim \mathrm{N}(\theta,\sigma^2)\) are independent and identically distributed normal random variables with unknown mean \(\theta\) and unknown variance \(\sigma^2\).
Compute the joint posterior distribution for \(\theta\) and \(\sigma^2\) using a conjugate prior distribution. Use a prior mean for \(\theta\) of \(8\) and an (imaginary) prior sample size of \(5\). Use \(\sigma_0^2 = 1^2\) and \(\nu_0 = 3\) degrees of freedom in your prior for \(\sigma^2\). Plot the marginal posterior distribution of \(\theta\).
Solution
The posterior distribution is given by \[ \begin{aligned} \theta | \sigma^2 , \boldsymbol{x} &\sim N\Big(\mu_n,\frac{\sigma^2}{\kappa_n}\Big) \\ \sigma^2 | \boldsymbol{x} &\sim \mathrm{Inv-}\chi^2(\nu_n,\sigma_n^2) \end{aligned} \] where \[ \begin{aligned} \mu_n &= w \bar x + (1-w)\mu_0 \\ w &= \frac{n}{\kappa_0+n} \\ \kappa_n &= \kappa_0 + n \\ \nu_n &= \nu_0 + n \\ \nu_n\sigma_n^2 &= \nu_0\sigma_0^2 + (n-1)s^2 + \frac{\kappa_0 n}{\kappa_0+n}(\bar x -\mu_0)^2 \end{aligned} \] We have
So the joint posterior is \[ \begin{aligned} \theta | \sigma^2 , \boldsymbol{x} &\sim N\Big(11.724,\frac{\sigma^2}{29}\Big) \\ \sigma^2 | \boldsymbol{x} &\sim \mathrm{Inv-}\chi^2(27,11.401) \end{aligned} \] The marginal posterior for \(\theta\) is \[ \theta \vert \boldsymbol{x} \sim t\Big(\mu_n,\frac{\sigma_n^2}{\kappa_n},\nu_n\Big) = t\Big(27,\frac{11.401}{29},27\Big) \] Plotting the marginal posterior of \(\theta\):
thetaGrid = seq(7, 18, length = 1000)
sigma2Grid = seq(0.001, 30, length = 1000)
dtdist <- function(x, mu, sigma2, nu){
return((1/sqrt(sigma2))*dt(x = (x - mu)/sqrt(sigma2), df = nu))
}
plot(thetaGrid, dtdist(thetaGrid, mun, sigman2/kappan, nun), type = "l",
xlab = expression(theta), ylab = "posterior density",
col = "indianred", main = expression(theta))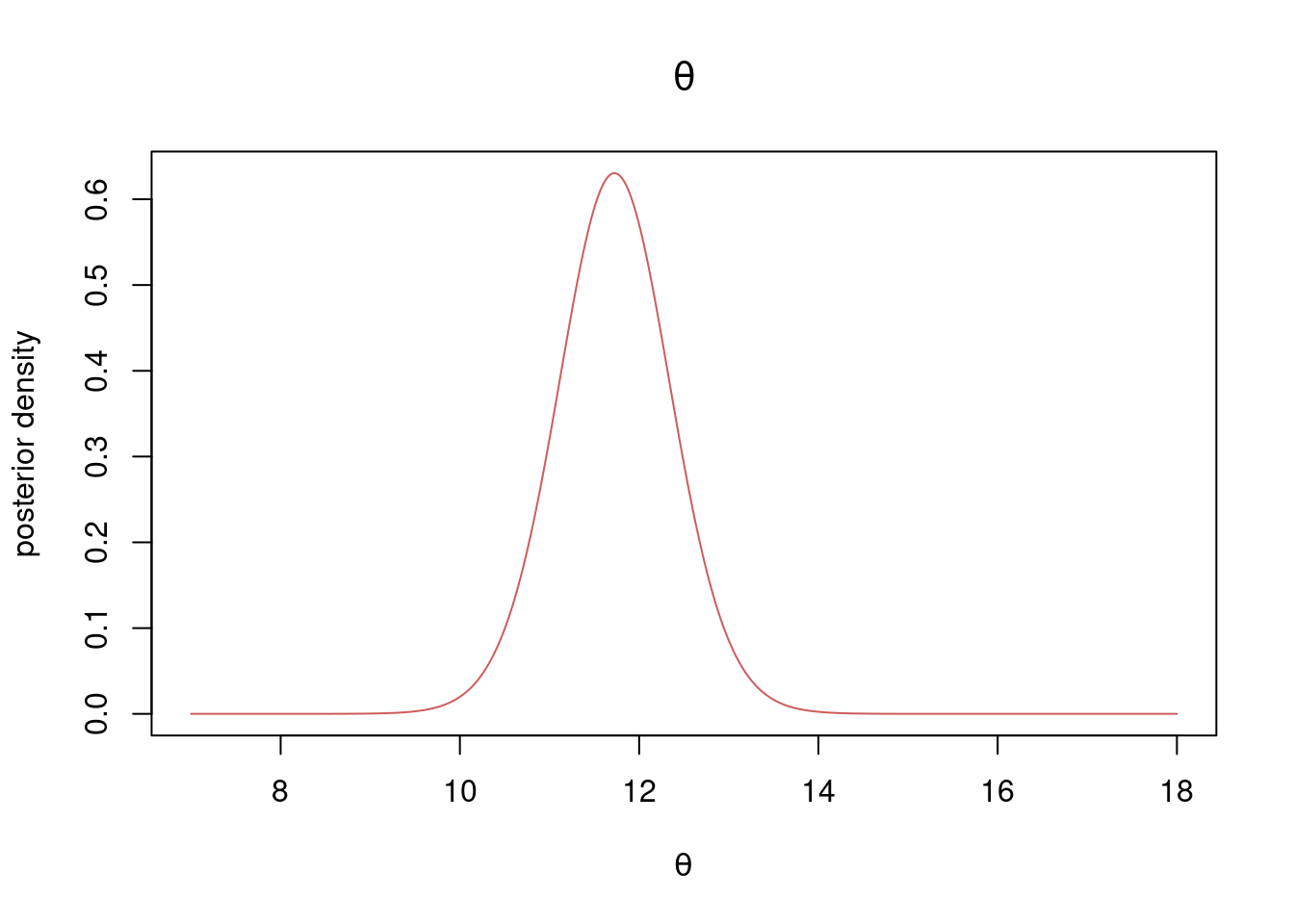
Exercise 3.3
Let \(X_1,\ldots,X_n \mid \theta,\sigma^2 \overset{\mathrm{iid}}{\sim} \mathrm{N}(\theta,\sigma^2)\), where \(\theta\) is assumed known. Show that the \(\mathrm{Inv-}\chi^2\) distribution is a conjugate prior for \(\sigma^2\).
Exercise 3.6
A Swedish poll in 2024 asked \(2311\) persons the question: The table below gives the poll results across the eight parties in parliament and the nineth option .
Let \(\boldsymbol{y} = (y_1,\ldots,y_9)\) denote the number of votes for each of the nine parties, where \(y_c\) is the number of votes for party \(c\). Model the data as iid from a multinomial distribution \[\begin{equation*} \boldsymbol{y} \mid \boldsymbol{\theta} \sim \mathrm{Multinomial}(n,\boldsymbol{\theta}), \end{equation*}\] where \(n=2311\) is the total number of respondents and \(\boldsymbol{\theta} = (\theta_1,\ldots,\theta_9)\) is the vector of voting proportions for each party, where \(\theta_c\) is the proportion of votes for party \(c\).
The previous election in 2022 resulted in the following voting percentages:
Use Dirichlet prior \(\boldsymbol{\theta} \sim \mathrm{Dirichlet}(\boldsymbol{\alpha})\) with \(\boldsymbol{\alpha} = (\alpha_1,\ldots,\alpha_9)\). Set the priorhyperparameters based on the election results from 2022, but assuming that the prior information is equivalent to only \(400\) respondents today.
a) What is the posterior distribution for the voting shares?
b) What is the marginal posterior distribution for the voting share of the S-party? Plot the distribution without resorting to simulation.
Solution
From the properties of the Dirichlet distribution box in the Bayesian Learning book, we know that if \((\theta_1,\ldots,\theta_C) \sim \mathrm{Dirichlet}(\alpha_1,\ldots,\alpha_C)\), then marginal distribution for the probability/proportion in category \(c\) is
\[
\theta_c \sim \mathrm{Beta}(\alpha_c, \alpha_+ -\alpha_c).
\] We can apply this result to get the marginal posterior for \(\theta_5\) (the proportion of S-voters), we just need to remember that the parameters in the posterior are \(\alpha_c + y_c\) for \(c=1,\ldots,C\), or alphaPost in the code. The marginal posterior for the proportion of S-party voters is \[
\theta_5 \vert \boldsymbol{y} \sim \mathrm{Beta}\Big(842.32, 1868.68 \Big),
\] which we can plot:
thetaGrid = seq(0, 1, length = 1000)
plot(thetaGrid, dbeta(thetaGrid, alphaPost[5], sum(alphaPost) - alphaPost[5]),
xlab = "proportion of S-voters", ylab = "posterior density", type = "l",
lwd = 3, col = "indianred")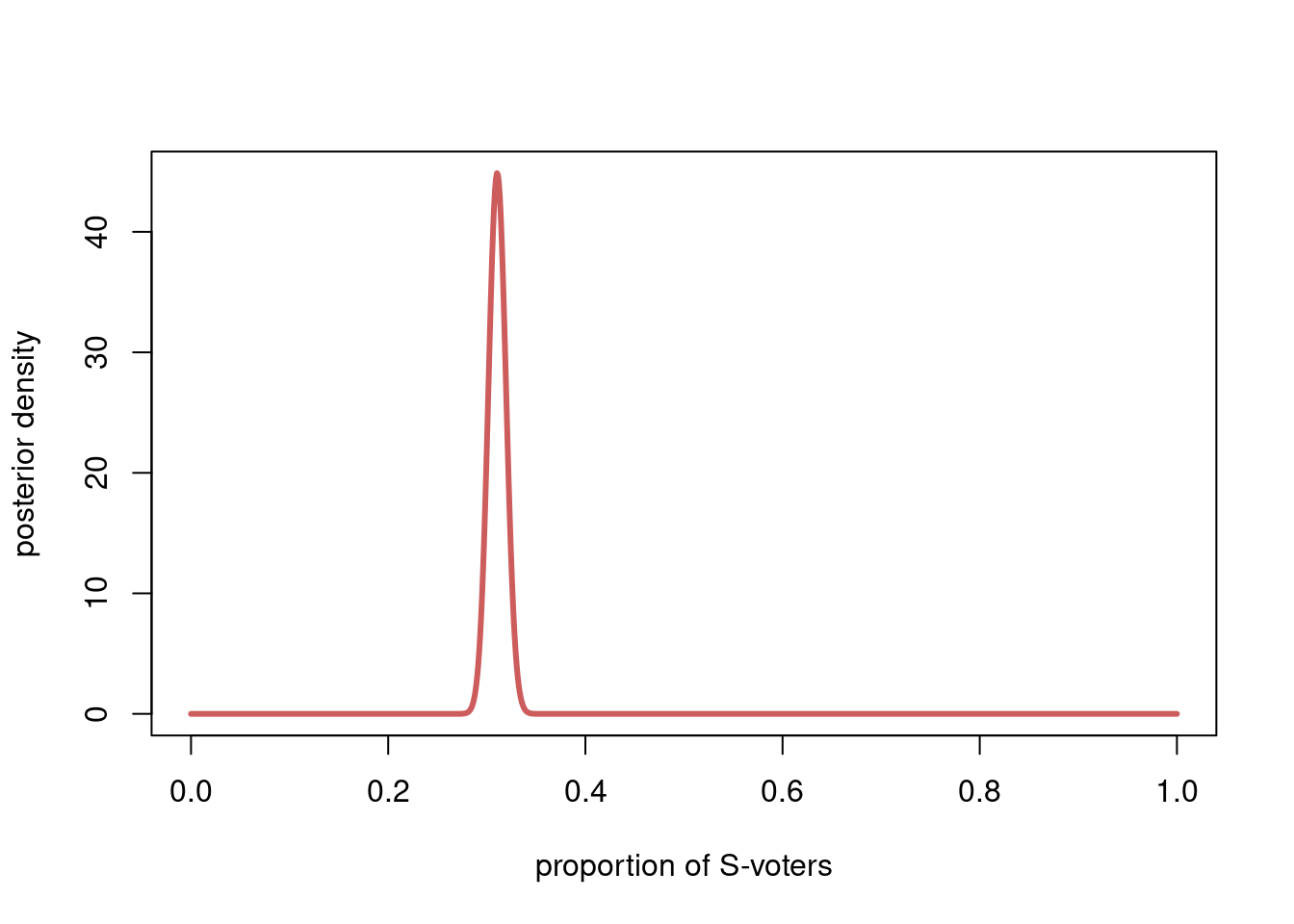
c) A party needs at least 4% of the votes to get into parliament. Use simulation to compute the posterior probability that both L and KD parties do not make it to parliament.
Exercise 3.7
The monthly income (in thousands Swedish Krona) of ten randomly selected persons are: 14, 25, 45, 25, 30, 33, 19, 50, 34 and 67. The log-normal distribution (see Box~ and ) is a commonly used model for income distributions. Let \(Y_1,\ldots,Y_n \vert \theta,\sigma^{2}\overset{\mathrm{iid}}{\sim}\mathrm{LN}(\theta,\sigma^{2})\), where \(\theta=\log(33)\) is assumed to be known but \(\sigma^{2}\) is unknown with non-informative prior \(p(\sigma^{2})\propto1/\sigma^{2}\). The posterior for \(\sigma^{2}\) given \(\theta\) is the \(\mathrm{Inv-}\chi^{2}(n,\tau^{2})\) distribution, where \[\begin{equation*} \tau^{2}=\frac{\sum_{i=1}^{n}(\log y_{i}-\theta)^{2}}{n}. \end{equation*}\]
a) Simulate \(10,000\) draws from the posterior of \(\sigma^{2}\), assuming \(\theta=\log(33)\) is known. Plot a histogram of the posterior draws of the \(\sigma\).
Solution
y = c(14, 25, 45, 25, 30, 33, 19, 50, 34, 67)
logy = log(y)
n = length(y)
theta = log(33)
tau2 = sum((logy - theta)^2)/n
# Defining a function that simulates nSim draws
# from the scaled inverse Chi-square distribution
rScaledInvChi2 <- function(nSim, df, scale){
return((df*scale)/rchisq(nSim, df=df))
}
nSim = 10000
sigma2Draws = rScaledInvChi2(nSim, n, tau2)
hist(sqrt(sigma2Draws), 100, col = "steelblue", main = "", freq = FALSE,
xlab = expression(sigma), ylab = "posterior density")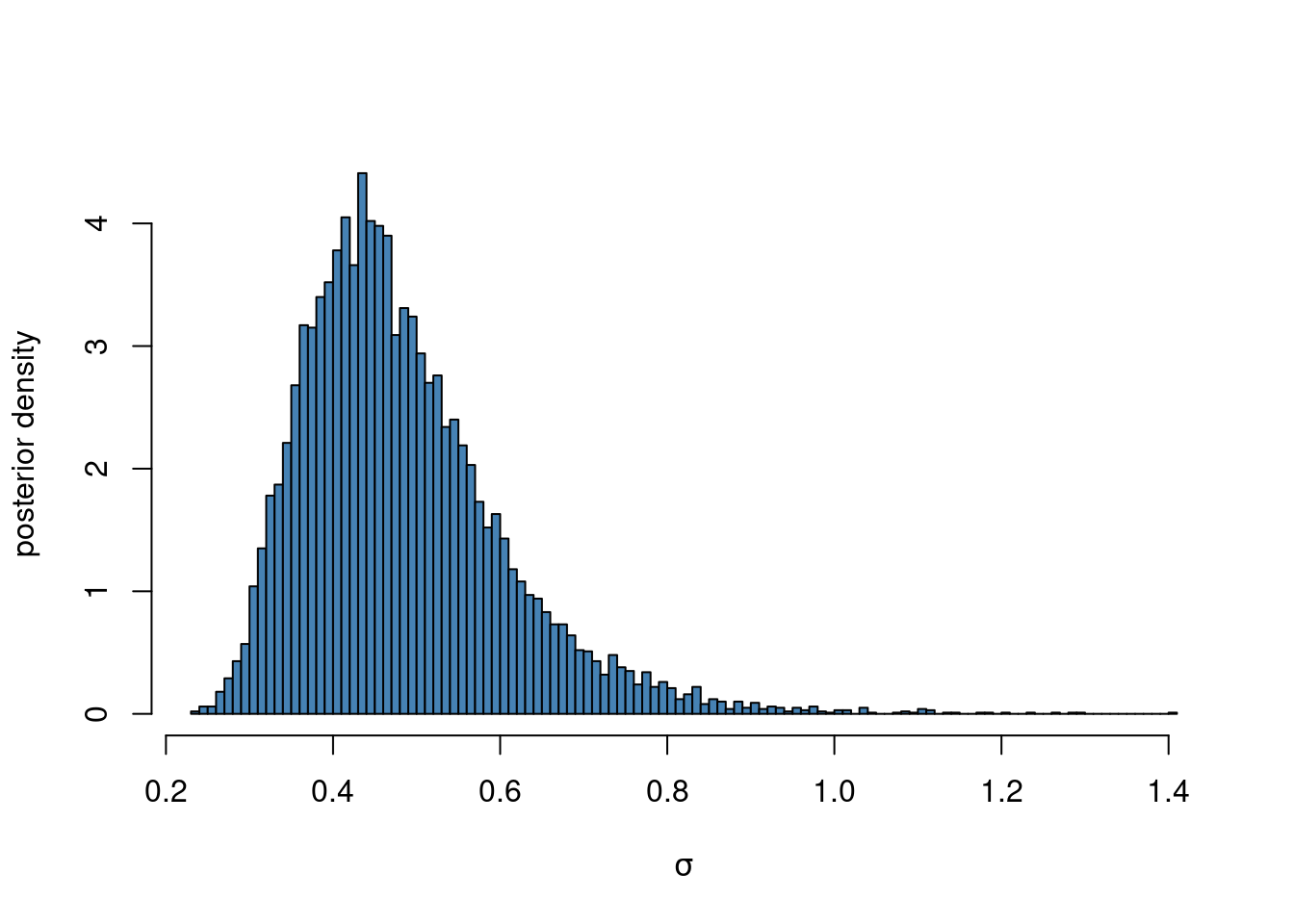
b) A commonly used measure of income inequality is the Gini coefficient, \(0\leq G\leq1\), where \(G=0\) is complete income equality, and \(G=1\) means complete income inequality. It can be shown that \(G=2\Phi\left(\sigma/\sqrt{2}\right)-1\) when incomes follow a \(\mathrm{LN}(\theta,\sigma^{2})\) distribution, where \(\Phi(z)\) is the cumulative distribution function (CDF) for the standard normal distribution. Use the posterior draws from a) to compute the posterior distribution of the Gini coefficient \(G\). Plot a histogram of the posterior draws of \(G\).
Solution
gini = rep(0, nSim)
for (i in 1:nSim){
gini[i] = 2*pnorm(sqrt(sigma2Draws[i])/sqrt(2)) - 1
}
hist(gini, 100, col = "cornsilk", main = "", freq = FALSE,
xlab = "Gini coefficient, G", ylab = "posterior density")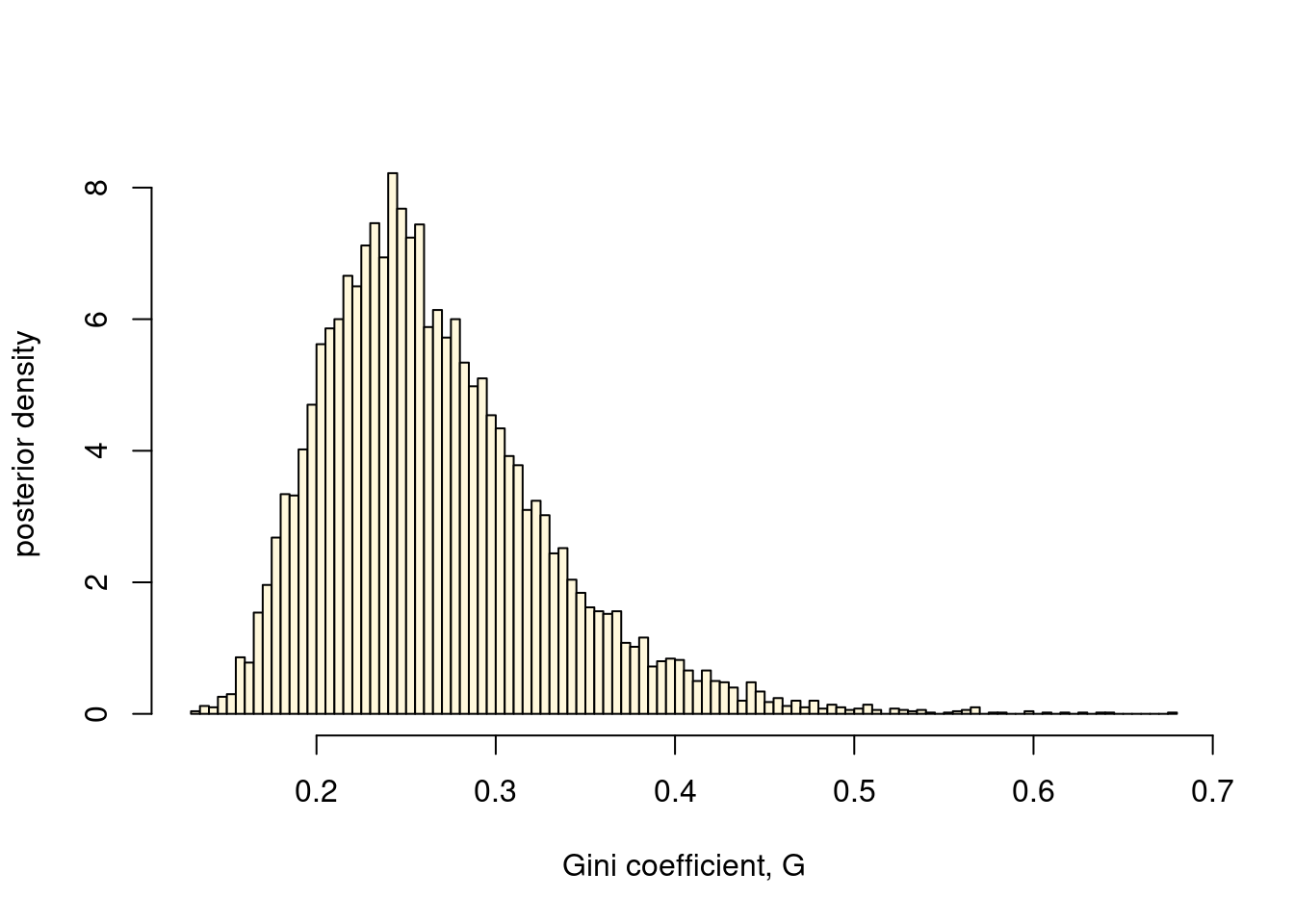
c) Compute a \(95\)% Highest Posterior Density (HPD) interval for \(G\). To compute the HPD interval you will need an estimate of the posterior density for \(G\); a common approach is to use a kernel density estimator, for example the density function in R.
Solution
We first estimate the posterior density from the posterior draws using a kernel density estimator, and plotting it on top of the histogram:
kde = density(gini)
giniGrid = kde$x
postDens = kde$y
hist(gini, 100, col = "cornsilk", main = "", freq = FALSE,
xlab = "Gini coefficient, G", ylab = "posterior density")
lines(giniGrid, postDens, lwd = 3, col = "indianred")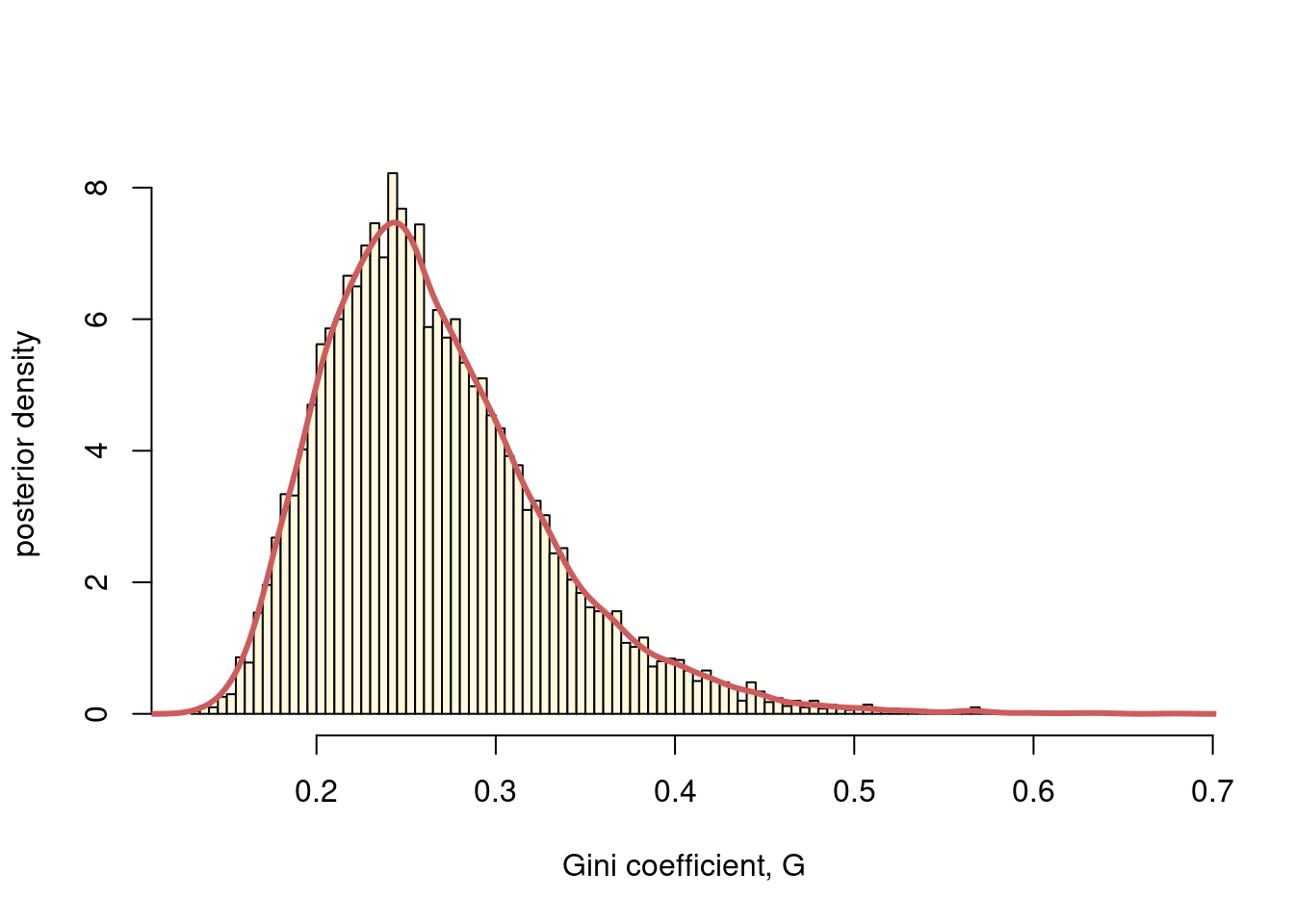
Now that we have the posterior density, and we can see that it is unimodal, we can use the same code as in the Solution to Exercise @q:iid_poisson_ambulance_b.
binWidth = giniGrid[2]- giniGrid[1]
# first, sort the density values from highest to lowest
postDensOrdered = sort(postDens, decreasing = TRUE)
# reorder the thetaValues so that they still match the density values
giniOrdered = giniGrid[order(postDens, decreasing = TRUE)]
cumsumPostDens = cumsum(binWidth*postDensOrdered) # posterior cdf
inHPD = which(cumsumPostDens < 0.95) # find highest pdf vals up to 95% quota.
hpd = c(min(giniOrdered[inHPD]), max(giniOrdered[inHPD]))
message(paste0("The 95% HPD interval for the Gini coefficient is (", hpd[1], ",", hpd[2],")"))The 95% HPD interval for the Gini coefficient is (0.159044415119536,0.392529484142363)