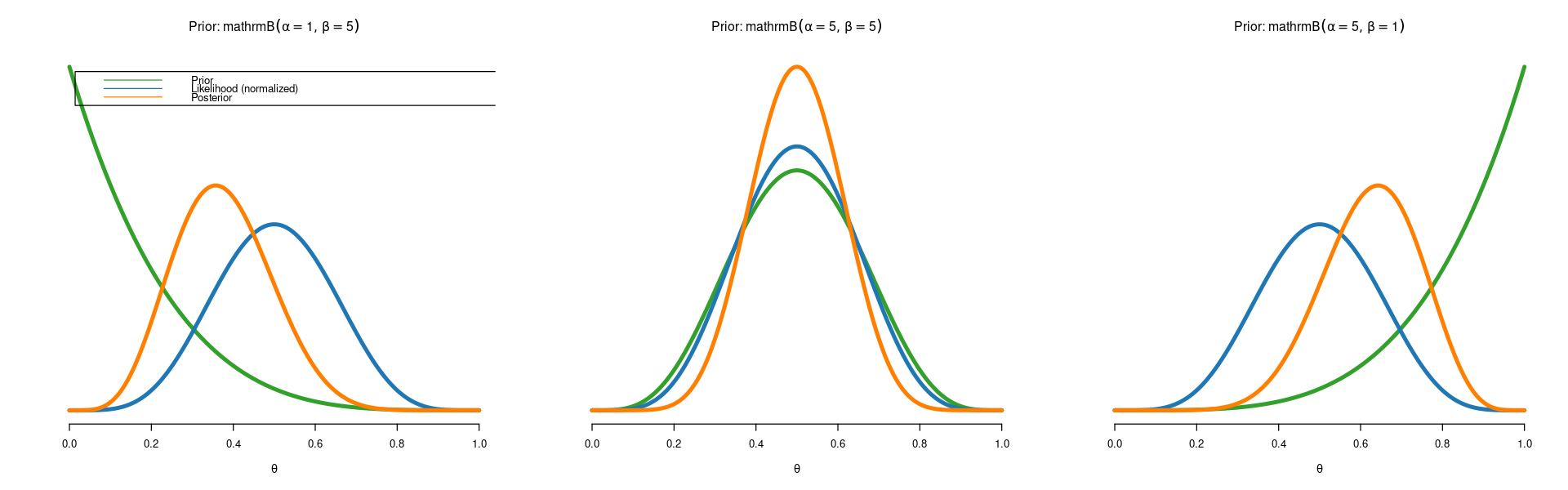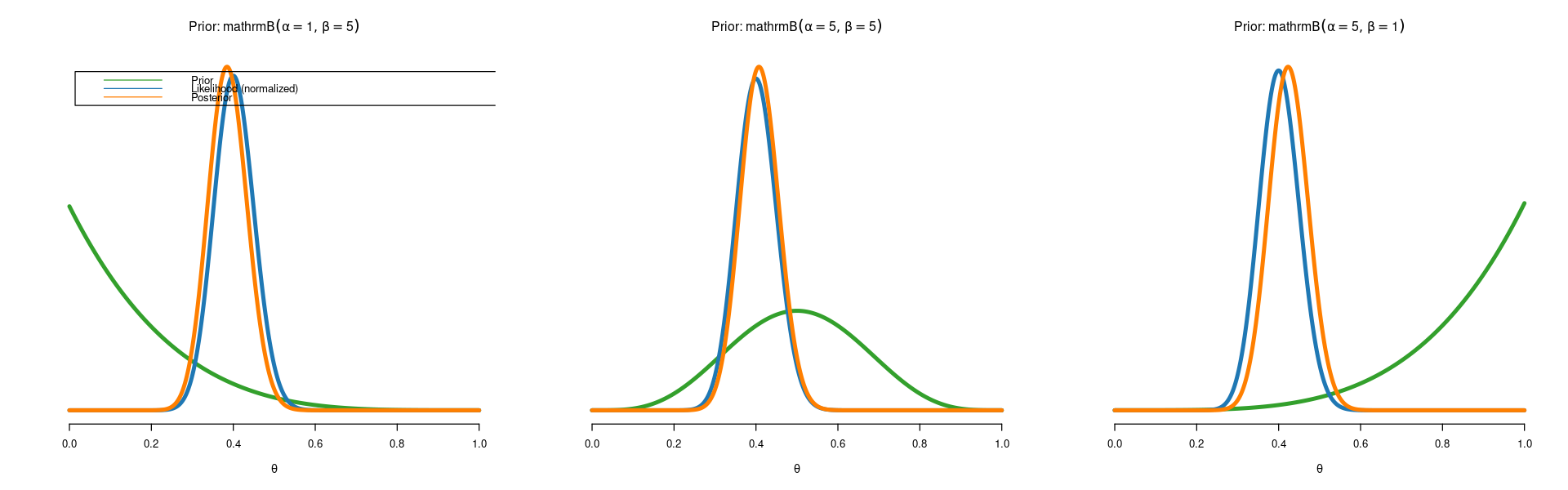The SpamBase dataset from the UCI repository consists of \(n=4601\) emails that have been manually classified as spam (junk email) or ham (non-junk email).
The dataset also contains a vector of covariates/features for each email, such as the number of capital letters or $-signs; this information can be used to build a spam filter that automatically separates spam from ham.
This notebook analyzes only the proportion of spam emails without using the covariates.
Getting started
First, load libraries and setting up colors.
options(repr.plot.width=16, repr.plot.height=5, lwd =4)library("RColorBrewer") # for pretty colorslibrary("tidyverse") # for string interpolation to print variables in plots.library("latex2exp") # the TeX() function makes it possible to print latex mathcolors =brewer.pal(12, "Paired")[c(1,2,7,8,3,4,5,6,9,10)];
── Attaching core tidyverse packages ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse 2.0.0 ──
✔dplyr 1.1.4 ✔readr 2.1.5
✔forcats 1.0.0 ✔stringr 1.5.1
✔ggplot2 3.5.2 ✔tibble 3.3.0
✔lubridate 1.9.4 ✔tidyr 1.3.1
✔purrr 1.1.0
── Conflicts ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖dplyr::filter() masks stats::filter()
✖dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Data
data =read.csv("https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/spambase.data", sep=",", header =TRUE)spam = data$X1 # This is the binary data where spam = 1, ham = 0.n =length(spam)spam =sample(spam, size = n) # Randomly shuffle the data.
Posterior mean is 0.375
Posterior standard deviation is 0.117
Posterior mean is 0.5
Posterior standard deviation is 0.109
Posterior mean is 0.625
Posterior standard deviation is 0.117
Since we only have \(n=10\) data points, the posteriors for the three different priors differ a lot. Priors matter when the data are weak. Let’s try with the \(n=100\) first observations.
Posterior mean is 0.387
Posterior standard deviation is 0.047
Posterior mean is 0.409
Posterior standard deviation is 0.047
Posterior mean is 0.425
Posterior standard deviation is 0.048
The effect of the prior is now almost gone. Finally let’s use all \(n=4601\) observations in the dataset:
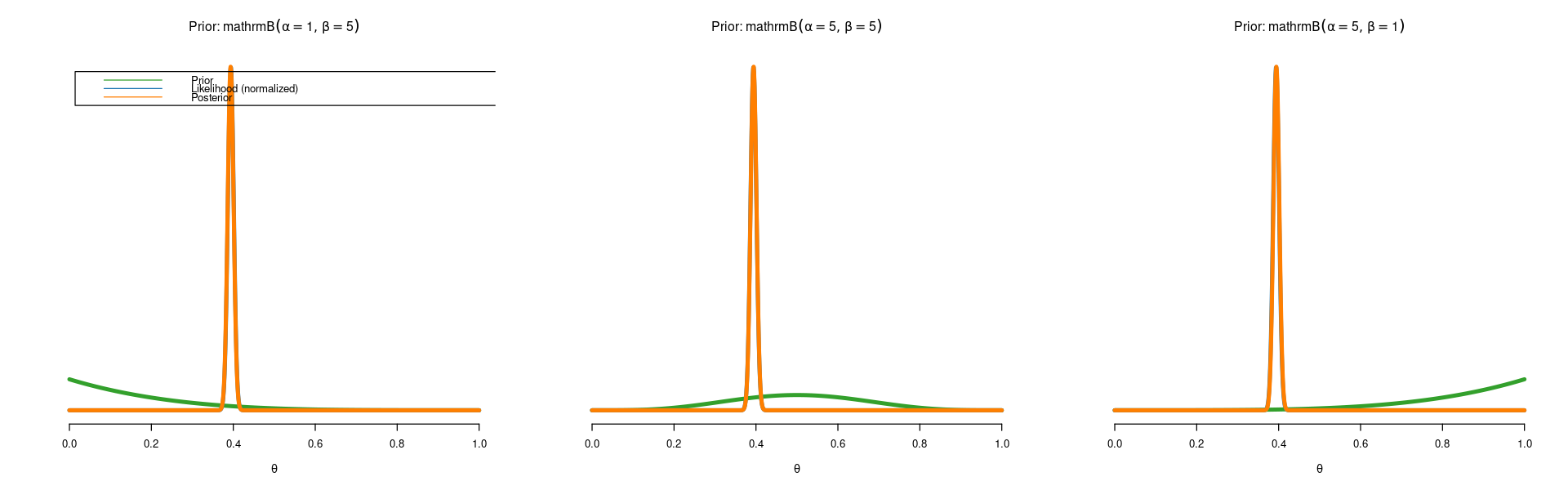
Posterior mean is 0.394
Posterior standard deviation is 0.007
Posterior mean is 0.394
Posterior standard deviation is 0.007
Posterior mean is 0.394
Posterior standard deviation is 0.007
We see two things: * The effect of the prior is completely gone. All three prior give identical posteriors. We have reached a subjective consensus among the three persons. * We are quite sure now that the spam probability \(\theta\) is around \(0.4\).
A later notebook will re-analyze this data using for example logistic regression.